
티스토리 뷰
개요
# 참고
DDD START! - 최범균 지음
도메인 주도 개발 시작하기! -최범균 지음
# 개요
DDD에 대한 기술서적을 읽고 DDD가 무엇인지 이해하고 어떻게 코드에 적용시킬 수 있는지 고민해 보려고 한다.
# 3장의 로드맵
- 애그리거트
- 애그리거트 루트와 역할
- 애그리거트와 리포지터리
- ID를 이용한 애그리거트 참조
3장. 애그리거트
도메인이 커질수록 많은 엔티티와 밸류가 나타나게 되며 점점 복잡해진다. 도메인 모델이 복잡해지면 개발자는 전체가 아닌 개별 요소에 집중하는 실수가 발생할 수 있다. 우리가 지도를 볼 때 대축적을 보면 전체 위치를 파악하기 쉽듯, 어그리게잇이 대축적 지도와 비슷한 개념이다. 애그리게잇을 통해 도메인 모델의 전체 구조를 파악하는데 도움이 될 수 있다.
애그리게잇은 관련 객체를 하나로 묶은 군집이다. 주문 도메인에는 "주문/배송지 정보/ 주문자/주문 목록/금액"의 하위 모델로 나눌 수 있다. 이 하위 개념을 표현하는 모델을 하나로 묶어서 주문이라는 상위 개념으로 표현할 수 있다. 따라서 어그리게잇을 통해 큰 틀에서 도메인 모델을 관리할 수 있다.
어그리게잇은 군집에 속한 객체를 관리하는 루트 엔티티를 갖는다. 루트 엔티티는 애그리게잇에 속해 있는 엔티티와 밸류 객체를 이용해서 어그리게잇을 구현해야 할 기능을 제공한다. 조금 더 설명한다면 어그리게잇 루트를 통해서 간접적으로 어그리게잇 내의 다른 엔티티나 밸류 객체에 접근한다. 이는 어그리게잇의 내부 구현을 숨겨서 어그리게잇 단위로 구현을 캡슐화 할 수 있도록 돕는다.
3-2. 애그리거트 루트
주문 Order 어그리게잇 루트에는 금액 밸류 타입과 수량 밸류 타입을 가지게 된다.
// 도메인 엔티티
public class Order{
private Value value; // 금액 밸류 타입
private Quantity quantity; // 수량 밸류 타입
private Orderer orderer; // 주문자 정보
private ShippingInfo shippingInfo; // 배송 정보
}
만약 주문자가 주문 수량을 변경하게 되면 어떻게 될까? 우리는 주문 수량만 수정하면 될까? 아니다. 금액도 변경해 주어야 한다. 어그리게잇은 여러 객체로 구성되기 떄문에 한 객체만 변경해 주면 안된다. 어그리게잇이 일관성을 가질수 있도록 관리해 줄 객체가 필요한데 그 것이 바로 어그리게잇 루트이다.
중요 개념을 먼저 설명하자면 어그리게잇을 일관성을 유지시키는 것이 중요하다. 조금 더 설명한다면 어그리게잇 루트를 통해서 간접적으로 어그리게잇 내의 다른 엔티티나 밸류 객체에 접근한다. 이는 어그리게잇의 내부 구현을 숨겨서 어그리게잇 단위로 구현을 캡슐화 할 수 있도록 돕는다.

이는 주문 도메인에서 상품 도메인을 참조하기 위해서는 반드시 어그리게잇 루트를 통해서만 접근해야 한다는 것이다. 만약 상품 도메인에서 주문 도메인의 결제 데이터를 참조하기 위해 결제에 직접적으로 접근하는 것은 데이터의 일관성을 깨트릴 수 있기 때문에 피해야 할 접근법이다.
따라서 어그리게잇 루트를 통해서만 도메인 로직을 구현하게 만들려면 도메인 모델에 대해 다음의 두 가지를 습관적으로 적용해야 한다.
1. 단순히 필드를 변경하는 set메서드를 public으로 만들지 않는다.
2. 밸류 타입은 불변으로 구현한다.
# 절대 피해야할 코드
// 도메인 엔티티
@Getter
public class Order{
private Value value; // 금액 밸류 타입
private Quantity quantity; // 수량 밸류 타입
private Orderer orderer; // 주문자 정보
private ShippingInfo shippingInfo; // 배송 정보
// 수량 변경
public void setQuantity(Quantity quantity) {
this.quantity = quantity;
}
//
}
public class Quantity {
int quantity; // 수량
int setCount; // 묶은 수량
public void setQuantity(int quantity) {
this.quantity = quantity;
}
}
public class OrderService{
// 비즈니스 로직 - 수량 변경
public void changeQuantity(){
Order order = new Order();
order.getQuantity().setQuantity(2); // <<< 이렇게 절대 하지 말자
}
}setQuantity로 수량을 직접 적으로 바꾸는 것이 어그리게잇의 일관성을 깨트리며, 어그리게잇 루트를 통한 접근이 아닌 하위 밸류 타입으로 직접 접근한다는 것이다.
Q. 그렇다면 어떻게 코드를 작성해야 할까?
A. 불변과 어그리게잇 루트를 통해 수정해 보자
# 밸류타입은 불변객체 / Setter는 private접근지정자 / 어그리게잇 루트를 통해 밸류타입 접근
@Getter
public class Order{
private Price price; // 금액 밸류 타입
private Quantity quantity; // 수량 밸류 타입
private Orderer orderer; // 주문자 정보
private ShippingInfo shippingInfo; // 배송 정보
public void changeSippingInfo(Quantity newQuantity, Price newPrice){
// 이미 배송중이라면 Exception
if(shippingInfo.shppingSatus.equals("NOW SHPPING~") ){
throw new IllegalArgumentException();
}
setQuantity(newQuantity); // 불변 타입 새로운 생성자 할당
setPrice(newPrice); // 불변 타입 새로운 생성자 할당
}
// 수량 변경
private void setQuantity(Quantity quantity) { // private 접근지정자 중요!
this.quantity = quantity;
}
// 가격 변경
private void setPrice(Price price) {
this.price = price;
}
}
public class Quantity {
int quantity; // 수량
int setCount; // 묶은 수량
public void setQuantity(int quantity) {
this.quantity = quantity;
}
}
@Getter
public class ShippingInfo {
String shppingSatus;
}
public class OrderService{
// 비즈니스 로직 - 수량 변경
public void changeQuantity(){
Order order = new Order();
Quantity newQuantity = new Quantity();
Price newPrice = new Price();
order.changeSippingInfo(newQuantity,newPrice);
}
}
위 코드에서 Order 엔티티 내부에 setter를 private를 사용함으로써 도메인 로직이 한 곳에 응집되게 하였다. 이렇게 함으로써 외부에서는 setter를 사용하지 못하게 하여 유지 보수할 때에도 분석하고 수정하는 시간을 줄일 수 있다. 또한 주문 수량을 변경할때 Quantity 클래스의 quantity 필드를 직접 수정하는 것이 아닌, 생성자를 통해 새로운 밸류 객체를 직접 할당 함으로써 일관성을 유지 시킬수 있도록 하였다.
취업을 준비하며 토이 프로젝트를 할때 가장 많이 착각한 것이 엔티티에는 도메인 로직이 들어가면 안 된다는 것이다. 하지만 어그리게잇 루트는 구성요소의 상태만 참조하는 것이 아니라 기능 실행을 하기도 한다. 실제로 "가격변경", "수량변경", "배송지 주소 변경"등 많은 부분을 구현할 수 있다. 여기서 기능을 구현한다는 말은 데이터베이스에 접근하는 그러한 것을 의미하는 것이 절대 아니며, 기능 실행을 의미하는 것이다.
3-2-1. 트랜잭션 범위
트랜잭션 범위는 작을수록 좋다. 한 트랜잭션이 한 개 테이블을 수정하는 것과 세 개의 테이블을 수정하는 것을 비교하면 성능에서 차이가 발생한다. 한 개 테이블을 수정하면 트랜잭션 충돌을 막기 위해 잠그는 대상이 한 개 테이블의 한 행으로 한정되지만, 세 개의 테이블을 수정하면 잠금 대상이 많아진다. 잠금 대상이 많아진다는 것은 그만큼 동시에 처리할 수 있는 트랜잭션 개수가 줄어든다는 것을 의미하고 이것은 전체적인 성능을 떨어트린다.
동일하게 한 트랜잭션에는 한 개의 애그리게잇만 수정해야 한다. 한 트랜잭션에서 두 개 이상의 어그리게잇을 수정하면 충돌이 발생할 가능성이 높아지기 때문에 성능이 떨어지게 된다.
Q. 그렇다면 AggregateService에 트랜잭션을 붙이면 될까?
Q. 무작정 어그리게잇 루트 엔티티에 트랜잭션을 적용하면 될까?
A. 아니다. 밸류 객체에서 다른 어그리게잇을 참고하고 있을 수 있다.
주문 어그리게잇 내에서 배송지 정보 변경을 생각해 보자. 이때 배송지 변경을 위해 회원 어그리게잇의 주소 정보로 설정할 수 있다. 이때 회원의 정보는 절대 변경해서는 안된다. 한 어그리게잇이 다른 어그리게잇의 기능을 변경하기 시작하면 결합도가 높아지고, 결합도가 높아질수록 향후 수정 비용이 증가하게 된다.
만약 부득이하게 수정해야 한다면, 어그리게잇에서 다른 어그리게잇을 직접 수정하지 말고 응용 서비스에서 두 어그리게잇을 수정하도록 구현해야 한다. 물론 도메인 이벤트(EDM, Kafka)를 사용하면 한 트랜잭션에서 두 개의 어그리게잇의 상태를 변경할 수도 있다.
Q. 수정이 아닌 조회는 직접해도 될까? 조회는 어그리게잇 루트를 직접 참조하지 않아도 되나? 물론 어그리게잇 루트에 식별자를 가지게 되는데, 밸류타입이 독립적인 테이블(엔티티)을 가지는 경우는?
3-3. 리포지터리와 애그리거트
애그리거트는 개념상 완전한 한 개의 도메인 모델을 표현하므로 객체의 영속성을 처리하는 레포지터리는 애그리게잇 단위로 존재한다. Order 어그리게잇 안에는 Orderer, ShippingInfo, Price 등 다양한 밸류 타입이 있으며 별도의 DB테이블에 저장한다고 해서 Orderer, ShippingInfo, Price의 Repository를 각각 만들지는 않는다. Orderer, ShippingInfo, Price는 Order의 구성요소이므로 Order를 위한 Repository만 존재한다.
| Q. 만약 레거시 시스템에서 밸류타입이 독립적인 엔티티 형태이면 어떻게 될까? A. 그래도 Repository는 Order하나만이다. 어그리게잇은 개념적으로 하나이므로 Repository는 어그리게잇 전체를 저장소에 영속화해야 한다. |
예를 들어 Oreder와 관련된 테이블이 6개라면 Order 어그리게잇을 저장할 때 어그리게잇 루트와 매핑되는 테이블뿐만 아니라 어그리게잇에 속한 모든 구성요소에 매핑된 테이블에 데이터를 저장해야 한다. Repository가 완전한 어그리게잇을 제공하지 않으면 필드나 값이 올바르지 않아 어그리게잇을 실행하는 도중에 NullPointException과 같은 문제가 발생할 수도 있다.
3-4. ID를 이용한 애그리거트 참조
애그리거트 관리 주체는 애그리거트 루트이므로, 애그리거트에서 다른 애그리거트를 참조한다는 것은 다른 애그리거트 루트를 참조한다는 의미와 같다. 즉, 위에서 설명한 것과 같이 다른 애그리거트를 참조하기 위해서는 애그리거트 루트를 통해서만 참조해야 한다는 의미이다.
Q. 그렇다면 주문 애그리거트에서 회원 애그리거트를 어떻게 참조해야 할까?
A. 필드 방식 먼저 살펴보자
//주문정보
public class Order{
private Orderer orderer;
}
//주문자 정보
public class Orderer{
private Member member; // << 필드방식
}
// 회원 정보
public class Member{
private int age;
private String name;
private String phone;
}필드를 이용해서 다른 애그리거트를 직접 참조하는 것은 개발자에게 구현의 편리함을 제공한다.
| Order.getOrderer( ).getMember( ).getName( ); |
다음과 같이 사용할 수 있으며 JPA의 @ManyToOne, @OneToOne과 같은 어노테이션을 이용해서 다른 애그리거트를 쉽게 참조할 수 있다.
하지만 필드를 이요한 애그리거트 참조는 다음 문제를 야기할 수 있다.
1. 편한 탐색 오용
2. 성능에 대한 고민
3. 확장의 어려움
# 편한 탐색 오용
애그리거트를 직접 참조할 때 발생할 수 있는 가장 큰 문제는 편리함을 오용할 수 있다는 거싱다. 한 애그리거트 내부에서 다른 애그리거트 객체에 접근할 수 있으면 다른 애그리거트의 상태를 쉽게 변경할 수 있게 된다. 트랜잭션 범위에서 언급한 것처럼 한 애그리거트가 관리하는 범위는 자기 자신으로 한정해야 한다.
public class Order{
private Orderer orderer; // 주문자 정보
}
public class Orderer{
private Member member;
public void changeMemberInfo(){
Orderer.getMember.changeMemberName();
}
}
public class Member{
private int age;
private String name;
private String phone;
}위 코드를 보면 Orderer에서 Member 객체를 손쉽게 변경할 수 있다. 한 애그리거트에서 다른 애그리거트의 상태를 변경하는 것은 애그리거트 간의 의존 결합도를 높여서 결과적으로 애그리거트의 변경을 어렵게 만듣다.
# 성능에 대한 고민
애그리거트를 직접 참조하면 성능과 관련된 여러가지 고민을 해야 한다. JPA를 사요하게 된다면 즉시로딩과 지연로딩을 선택할 수 있는데, 단순히 연관된 객체의 데이터를 함께 화면에 보여줘야 하면 즉시로딩이 유리하고, 애그리거트의 상태를 변경하는 기능을 실행하는 경우에는 불필요한 객체를 함께 로딩할 필요가 없으므로 지연로딩이 유리할 수 있다.
# 확장의 어려움
초기에 단일 서버에 단일 DBMS로 서비스를 제공하다 사요자가 몰리기 시작하면, 자연스럽게 트래픽이 증가하고 부하를 분산하기 위해 시스템을 분리하기 시작한다.(MSA) 이 과정에서 하위 도메인마다 서로 다른 DBMS를 사용할 때도 있다. MSSQL, REDIS, MongoDB드 다양한 데이터 베이스를 참조할 수 있는데, 이때 필드 참조 방싱은 다른 애그리거트 루트를 참조하기 위해 JPA와 같은 단일 기술을 사용할 수 없음을 의미한다.
# 해결법
이런 세 가지 문제를 완화할 때 사용할 수 있는 것이 ID를 이용해서 다른 애그리거트를 참조하는 것이다.
//주문정보
public class Order{
private Orderer orderer;
}
//주문자 정보
public class Orderer{
private MemberId memberId; // << ID를 이용한 간접 참조
}
// 회원 정보
public class Member{
private MemberId id;
}ID참조를 사용하면 모든 객체가 참조로 연결되지 않고 한 애그리거트에 속한 객체들만 참조로 연결된다. 이는 애그리거트 경계를 명확히 하고 애그리거트 간 물리적인 연결을 제거하기 때문에 모델의 복잡도를 낮춰준다.
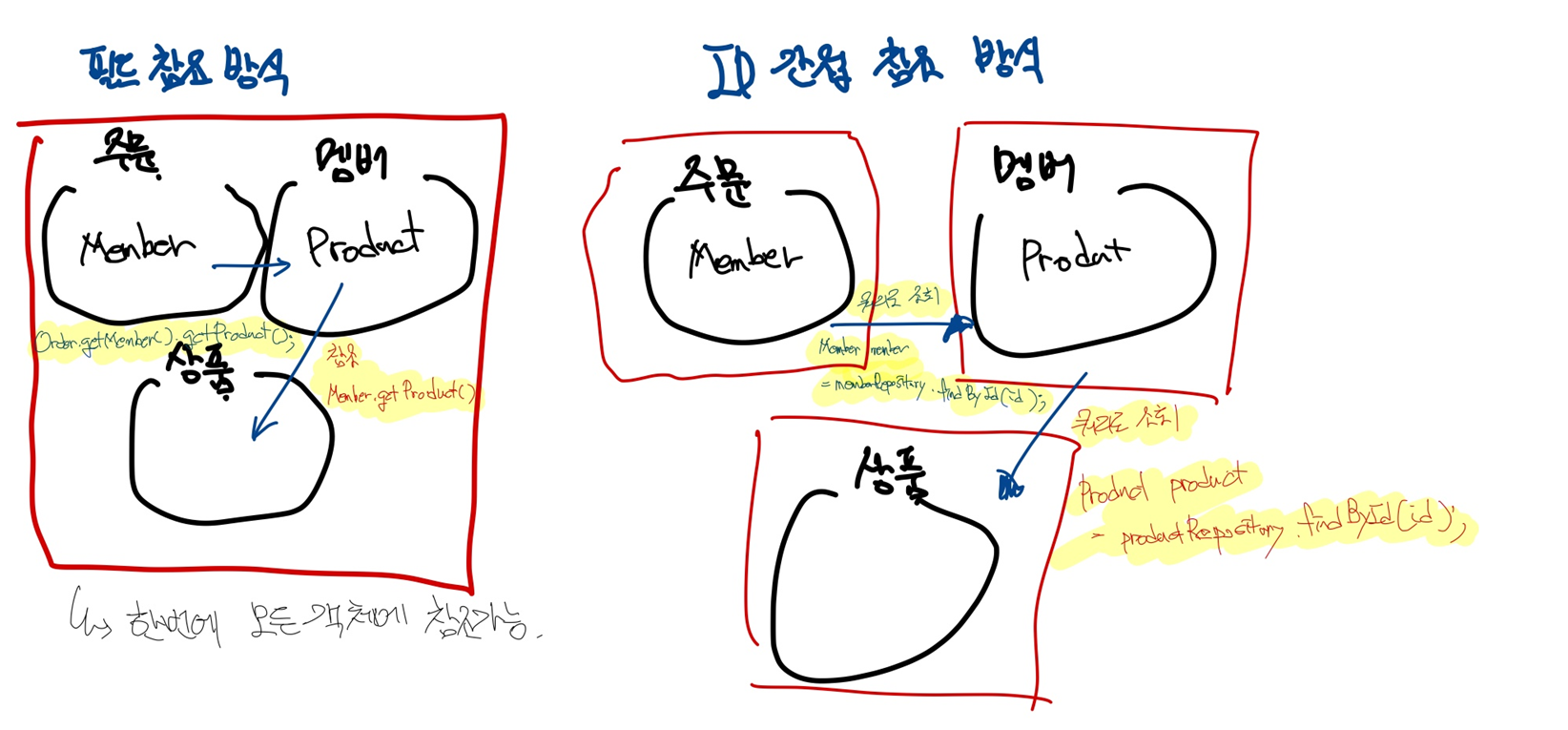
또한 구현 복잡도도 낮아진다. 다른 애그리거트를 직접 참조하지 않으므로 애그리거트 간 참조를 지연로딩으로 할지 즉시로딩으로 할지 고민하지 않아도 된다. 참조하는 애그리거트가 필요하면 응용 서비스에서 ID를 이용해서 로딩하면 된다. 응용서비스에서 필요한 시점에 Member애그리거트를 로딩하므로 애그리거트 수준에서 지연로딩을 하는 것과 동일한 결과를 만든다.
public class Order{
private Orderer orderer;
}
public class Orderer{
private Member member;
}
public class Member{
private int age;
private String name;
private String phone;
}
@Service
@RequiredArgsConstructor
public class OrderService(){
private final MemberRespository memberRespository;
public void changeShipping(){
// 중요!! ID를 이용한 간접 참조
Member member = memberRespository.findById(order.getOrderer().getMemberId());
}
}
# 의존관계를 낮추는 장점
ID를 이요하 참조 방식을 사용하면 복잡도를 낮추는 것과 함께 한 애그리거트에서 다른 애그리거트를 수정하는 문제를 근본적으로 방지할 수 있다.
orederer.getMember( ).setProduct( )
# 확장의 편리함
애그리거트 별로 다른 구현기술(데이터 저장소)를 사용하는 것도 가능해 진다. 중요한 데이터인 주문 애그리거트는 RDBMS에 저장하고 조회 성능이 중요한 상품 애그리거트는 NoSQL에 저장할 수 있다.
# 정리
즉, 다른 애그리거트 사용할 때는 필드 방식 보다는 해당 ID값을 필드변수로 사용하고, repository.findById( )를 이용해서 쿼리문으로 조회하거 수정하는 것이 좋다.
Q. 주문 애그리거트에서 상품 애그리거트를 수정해도 되나? 조회만 해야 하나?
3-4-1. ID를 이용한 참조와 조회 성능 (N+1문제)
다른 애그리거트를 ID로 참조하면 참조하는 여러 애그리거트를 읽을 때 조회 속도가 문제 될 수 있다. 한 DBMS에 데이터가 있다면 조인을 이용해서 한 번에 모든 데이터를 가져올 수 있음에도 불구하고 주문마다 상품 정보를 읽어오는 쿼리를 실행하게 된다.
이렇게 되면 간혹 N+1문제가 발생하게 된다. N+1문제는 주문 개수가 10개면 주문을 읽어오기 위한 1번의 쿼리와 주문별로 각 상품을 읽어오기 위한 10번의 쿼리를 실행한다. '조회 대상이 N개일 때 N개를 읽어오는 한 번의 쿼리와 연관된 데이터를 읽어오는 쿼리를 N번 실행한다' 해서 이를 N+1 조회 문제라고 부른다. ID를 이용한 애그리거트 참조는 지연로딩과 같은 효과를 만드는데 지연로딩과 관련된 대표적인 문제가 N+1조회 문제이다.
N+1은 조회 속도가 느려지는 원인이기 때문에 이를 해결하기 위해서는 조인을 사용해야 한다. 하지만 조인을 사용하는 것은 ID참조방식에서 객체참조 방식으로 바꾸고 즉시로딩을 사용하도록 매핑 설정을 바꾸는 것이다. ID참조 방식을 사용하면서 N+1 조회와 같은 문제가 발생하지 않도록 하려면 조회 전용 쿼리를 사용하면 된다.
조회 전용 쿼리는 JPQL사용을 의미한다. JPQL에서 역시 회원, 상품, 주문 테이블을 조인을 통해 한 번의 쿼리로 로딩한다. 즉시로딩이나 지연로딩을 고민할 필요없이 조회 화면에서 필요한 애그리거트 데이터를 한 번의 쿼리로 로딩할 수 있다. 쿼리가 복잡하거나 SQL에 특화된 기능을 사용해야 한다면 조회를 위한 부분만 마이베티스와 같은 기술을 이용해서 구현할 수도 있다.
Q. 그렇다면 MyBatis는 N+1문제가 발생하지 않는 것인가?
# 분리된 저장소의 조회 성능
애그리거트마다 서로 다른 저장소를 사용하면 한 번의 쿼리(JOIN)로 관련 애그리거트를 조회할 수 없다. 이때는 조회 성능을 높이기 위해 캐시를 적용하거나 조회 전용 저장소를 따로 구서해야 한다. 하지만 이 방법은 코드가 복잡해지는 단점이 있지만 시스템의 처리량을 높일 수 있다는 장점이 있다. 특히 한 대의 DB장비로 대응할 수 없는 수준의 트래픽이 발생하는 경우 캐시나 조회 전용 저장소는 필수로 선택해야 하는 기법이다.
3-5. 애그리거트 간 집합 연관
컬렉션과 페이징에 대한 내용. 추후 4장에서 상세히 다룸
3-6. 어그리거트를 팩토리로 사용하기
회원가입 로직에서 아이디 중복체크를 해서 동일한 아이디는 사용하지 못하도록 하는 기능을 구현한다고 생각 해보자. 보통은 응용 서비스에 아이디 중복체크를 구현할 것이다. 이러한 방식은 나쁜 코드는 아니지만 Member를 생성가능한지 판단하는 코드와 Member를 생성하는 코드가 분리되어 있다. 코드가 나빠 보이지는 않지만 중요한 도메인 로직 처리가 응용서비스에 노출된다. 또한 회원가입을 통해 Member를 생성하여 회원가입을 하고 아이디 중복체크를 하는 것은 논리적으로 하나의 도메인 기능이다.
@Service
@RequiredArgsConstructor
public class OrderService(){
private final MemberRespository memberRespository;
public void signIn(){
// 아이디 중복 체크
if (checkIsDuplicateId()){
throw new DuplicateRequestException("아이디 중복");
}
// 회원가입
memberRespository.save(member);
}
}
이를 위해 팩토리를 구현할 수 있지만 애그리거트를 팩토리로 사용할 수도 있다.
public class Member{
public Member checkDuplicateId(SignInRequest request){
// 아이디 중복 체크
if (checkIsDuplicateId()){
throw new DuplicateRequestException("아이디 중복");
}
return member;
}
}
@Service
@RequiredArgsConstructor
public class OrderService(){
private final MemberRespository memberRespository;
public void signIn(SignInRequest request){
// 아이디 중복 체크와 회원가입이 하나의 로직
Member member = new Member();
member = member.checkDuplicateId(request);
memberRespository.save(member);
}
}앞선 코드와의 차이점은 더 이상 응용 서비스에서는 아이디 중복체크를 하지 않고, 애그리거트에서 아이디 중복체크를 하면서 논리적으로 하나의 도메인으로 합쳤다. 또한 아이디 중복체크 기능이 변경되더라도 응용서비스에는 코드 변화가 전혀 생기지 않아 응집력을 높일 수 있다. 이것이 애그리거트를 팩토리로 사용하면 얻을 수 있는 장점이다.