
티스토리 뷰
Q. 질문
Spring의 웹 3계층을 공부하며 DAO가 Repository계층에 속한다는 블로그의 글을 본적이 있다. 정말 DAO와 Repository는 같을까?
A. 설명
Dao와 Repository의 차이점을 이해하기위해 필요한 선행지식은 다음과 같다.
1. 객체지향
2. DAO
3. DDD
4. 기본적인 웹 설계 구조
DAO가 만들어진 목적을 이해하기 위해서는 객체지향적 설계법이 대한 지식이 수반되어야 한다. 또한 Repository를 이해하기 위해서는 DDD를 알아야 한다.
왜냐하면 DDD에서 Repository라는 개념이 튀어나왔기 때문이다.
실제로 스프링 프레임워크의 @Repository 어노테이션을 들어가서 보면 다음과 같이 명시되어 있다.
Indicates that an annotated class is a "Repository", originally defined by Domain-Driven Design (Evans, 2003) as "a mechanism for encapsulating storage, retrieval, and search behavior which emulates a collection of objects".
"개체 모음을 모방하는 스토리지, 검색 및 검색 동작을 캡슐화하는 메커니즘"입니다.
A. DAO
Q. DAO란 무엇일까?
DAO(Data Access object)는 스프링의 아버지라 부를 수 있는 J2EE에서 등장한 개념이다. 에플리케이션을 사용하다보면 영구저장소(Oracle, Mysql, MongoDB...) 매커니즘이 필요할때가 매우 많아진다.
어플리케이션에서 영구저장소에 접근하기 위해서는 영구 저장소 밴더에서 제공하는 API를 통해서 접근하면 된다. 하지만 이 방식의 문제점은 무엇일까?,
첫번째, 구현체와 로직이 너무 강한 결합을 가지게 된다.
만일 내가 영구 저장소를 Mysql을 쓰고 있을때, 영구저장소를 Oracle로 바꿔야 한다면, 우리는 Mysql의 API를 사용한 모든 구현을 변경해야 한다. 즉, 변경에 자유롭지 않다. (OCP위반)
두번째, 레이어가 깨진다.
일반적으로 웹 어플리케이션을 만들 때 우리는 레이어를 나눠서 설계를 진행한다.
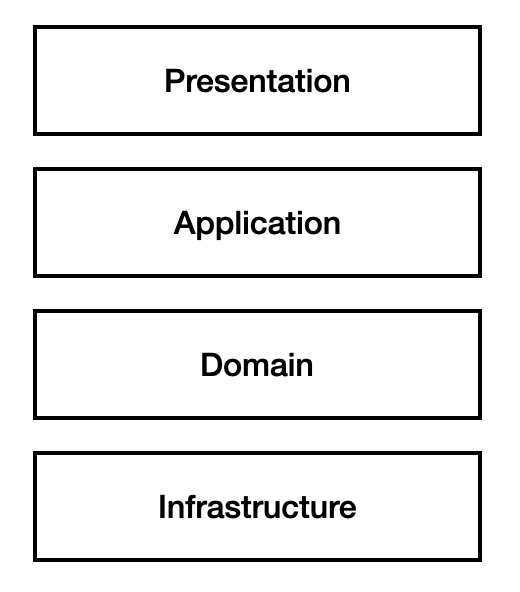
일반적인 웹 어플리케이션의 아키텍쳐
표현계층은 view, 응용 계층은 service, 도메인은 비스니스 로직(도메인), infrastructure는 db, 외부 라이브러리등 어플리케이션을 만드는데 필요한 인프라들을 의미한다. 흔히 퍼시스턴트 레이어라고 부르는게 인프라 스트럭쳐에 속해있다고 말할 수 있다.
이때, 우리의 예시에서 Mysql의 Api를 서비스 로직에서 사용하기 위해 Application계층에서 new키워드를 생성했다고 가정해 보자. 이 순간 service로직을 담당하는 객체와 db와 관련된 api가 강한 결합을 가지며, 영속성과 관련된 로직이 서비스 로직에 생성된다. 즉, 인프라와 응용계층이 섞여 버리는 일이 발생한다.
세번째. 개발자의 러닝커브가 증가한다.
밴더마다 자신의 영구저장소의 API설계가 완전히 동일할 수는 없다. 회사마다, 그리고 그 특징마다 서로 다른 구현을 가진다. 즉, 새로운 밴더의 API를 사용할 때 마다 사용자에게 학습에 대한 부담을 증가시키며 러닝커브를 향상시킨다.
Q. 3가지 문제를 어떻게 해결할까?
이런 문제점을 해결하기 위해 나온 패턴이 DAO 패턴이다. DAO는 밴더들의 API와 로직 사이에 있는 어댑터 패턴과 같은 역할을 한다.
먼저, DAO가 어뎁터의 역할을 수행함으로써 밴더들 사이의 구현의 차이점을 극복했다. 이를 통해 세번째 문제점을 해결할 수 있었다. 또한 이를 통해 얻을 수 있는 이점으로 강한 결합을 해결했다. 밴더의 구현체를 그대로 사용하는 것이 아니라 DAO라는 객체로 한번 더 감쌈으로서 내가 사용하는 데이터소스가 변경되더라도 그 로직에는 변화가 없도록 하였다. 이를 통해 첫번째, 세번째 문제점을 해결했다.
그러면 2번째 문제는 어떻게 해결했을까? 이는 DAO의 시퀀스 다이어그램을 보면 알 수 있다.
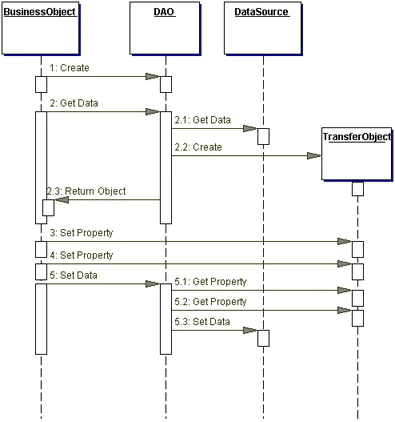
그림을 보면 데이터를 가지고 오는데 있어서 TransferObject를 사용하는것을 볼 수 있다. 이는 우리가 주로 말하는 DTO와 같은 개념이다(혹은 VO라고 알고있을 수 도 있다. 하지만 엄밀히 말하면 이런 계층간의 데이터이동을 위해 사용되는 객체는 TO 또는 DTO가 맞다. VO는 J2EE의 초판에서 TO를 부르던 말이며, 이는 후에 TO로 재명명 되었다. 또한 마틴파울러 또한 같은 개념을 제시했는데, 마틴파울러는 이러한 객체를 DTO라고 불렀다. 이때 마틴파울러는 VO라는 개념을 새롭게 제시하였다. 따라서 현재 우리가 VO라고 명명한다면 마틴파울러의 정의를 따라야 하는데, 이는 TO와는 전혀 다른 개념이므로 데이터 전송을 위한 객체를 VO라 부르는 것은 적절하지 않다.).
그렇다. J2EE에서는 데이터를 어플리케이션 layer로 전송하기 위해 TO를 사용했다. 이를 통해 레이어가 깨지는 것을 방지했다.
DTO는 말 그대로 "데이터"를 전송하기 위한 객체이다. Entity 그 자체를 전송해서는 안된다. DAO를 사용하는데 그 반환값으로 도메인객체(Entity)를 바로 내보내거나, DAO로 데이터를 저장하는데 Entity를 그대로 인수로 받는 경우가 있는데, 이는 완전히 잘못된 구현이다. 서로간의 레이어를 존중해야한다.
A. Repository
Q. Repository란 무엇인가?
Repository는 DDD에서 처음 등장한 개념이다. 많은 사람들이 Repository를 객체의 컬렉션이라고 부른다.
Repository는 과연 어느 레이어에 속할까? 공부를 조금 한 사람들은 도메인이라고 말 할 것이다.
이상하다. 우리는 보통 Repository를 DB와 같은 영구저장소를 사용하기 위해 사용하는데, 왜 도메인 레이어에 속한다고 말하는 걸까?
직관대로 생각해보자. Repository를 우리가 평소 사용하는 용도대로 생각해 보자, 그러면 이는 Infrastructure 레이어에 속해야 적당할 것이다.
원칙적으로 Repository는 객체의 상태를 관리하는 저장소이다. 즉, Entity 그 자체를 저장하고 불러오는 역할을 한다. 그러니 당연하게 Repository는 도메인레이어에 대한 지식을 알고 있어야 한다.
그런데 생각해보라, 우리는 Repository를 Infrastructure 레이어라고 정의했는데, 도메인의 정보를 알고 있어야 한다고? 그러면 도메인 레이어와 인프라스트럭처 레이어가 섞이는 것 아닌가???(즉, 계층이 깨진다)
여기서 부터 우리의 혼돈이 시작된 것이다.
정확히, Repository는 영구저장소를 의미하는게 아니다. 말 그대로, 객체의 상태를 관리하는 저장소일 뿐이다. 즉, Repository의 구현이 파일시스템으로 되든, 아니면 HashMap으로 구현됐든지 상관없다. 그냥 객체(entity)에 대한 CRUD를 수행할 수 있으면 된다.
Repository가 영구저장소라는 생각을 버려라. 그냥 컬랙션이라 생각해라. 우리가 HashMap을 사용하는데 이를 Infrastructure 레이어라고 생각하는가? 아니다. 그냥 그렇게 생각해라. 객체를 위한 컬렉션일 뿐이다.
컬렉션을 사용하는데 있어서 우리는 내부 구현을 신경쓰지 않는다. 그냥 그 퍼블릭 메소드만 확인하고, 제공해 주는 기능을 사용하면 된다.
이와같은 이유로 일반적으로 Repository의 인터페이스를 도메인 로직에 넣어둔다. 여기서 바로 Repository는 도메인 레이어라는 말이 나온것이다. 즉, 인터페이스가 도메인 레이어에 속한다.
(살짝 말하자면, 어플리케이션 계층에 넣지 않는 이유는 계층구조를 깨트리지 않기 위함이다.).
하지만 Repository는 보통 서비스 로직에서 사용한다. 도메인 로직(비즈니스 로직)에서는 Repository를 사용하기 어렵고, 추천도 안한다. 그런데 왜 어플리케이션 레이어가 아니라 도메인 레이어라고 말할까? 이에대한 내용은 어그리거트, 모듈, 계층과 관련되어 있다. 하지만 이번 장은 DDD에 대한 내용이 아니므로 여기서는 생략하고 추후 따로 업로드 하도록 하겠다. 일단은 레포지토리는 도메인 레이어라는 사실만을 알아두라.
모듈은 고수준모듈에서 저수준 모듈에 의존하게 된다. 따라서 도메인 레이어에 속해있는 Repository를 Application레이어에서 사용하는건 전혀 어색하지 않다. 따라서 서비스로직에서 Repository의 인터페이스를 사용할 수 있게 된다.
그래, Repository는 영구저장소가 아니다는건 알겠다. 그런데 우리는 이를 영구저장소 처럼 사용한다. 이는 어떻게 된 것인가? 그 비밀은 바로, Repository의 구현체를 영구저장소 API를 이용해 구현한 것에 있다. 위에서 말했듯, Repository를 사용하는 클라이언트는 Repository가 어떻게 구현되어 있는지 모른다. 단지, 그 기능을 사용할 뿐이다. 하지만, 실제로 바인딩 되는 콘크리트 객체는 인프라 스트럭쳐 레이어에 속해 있는 것 이다.
그러면 또 계층이 섞이는게 아닌가 궁금할 것 이다. 하지만 이걸 생각해보라. 클라이언트는 Repository의 인터페이스만을 사용한다. 따라서 그 구현을 모른다고 말했다. DAO와 같다. 구현을 숨김으로써 로직을 한곳으로 응집시켰다(캡슐화). 따라서 서비스로직에서는 "도메인"의 레포지토리(컬렉션)을 사용한 것 뿐이다. 영속성과 관련된 로직은 전혀 모른다. 또한 인프라 스트럭처와 관련된 모듈 또한 전혀 import되지 않는다. 따라서 계층이 깨지는 일은 없다.
즉, 우리가 일반적으로 사용하는 관점에서 Repository의 Interface는 도메인 레이어, Repository의 구현체는 영속성 레이어에 속한다 이를 통해 도메인 레이어와 인프라스트럭처 레이어의 의존성이 뒤집힌다(DIP). 따라서 이젠 인프라스트럭처 레이어에서 도메인의 지식을 알아도 괜찮으며 이를 통해 Entity를 영속성 로직에 포함시킬 수 있게 되는 것 이다.
이제 결론을 내 보자.
간단하다. 둘을 너무나도 다르면서 비슷하다.
나는 이렇게 결론을 내고싶다.
DAO는 자신이 영속성객체라는것을 숨기지 않는다. 이름에서 그 의도를 바로 나타낸다. 자신이 인프라 스트럭쳐 레이어에 있다는 걸 숨기지 않는다. 또한 계층(모듈)의 의존성을 봤을 때 도메인이 인프라 스트럭쳐에 의존한다. 따라서 DAO를 이용해 바로 entity를 컨트롤 하는것은 계층을 무너트리고 잘못된 사용이다. 항상 DTO를 사용하여 데이터를 주고받아야 한다(같은 이유로 DTO에 Entity를 넣어서 보내는 행위 또한 안된다.)
그에 반해, Repository는 자신이 영속성 객체임을 숨긴다. 자신이 인프라 스트럭처 레이어에 있다는 것을 숨긴다. 또한 의존성이 역전되어 있기 때문에, entity를 그대로 가져와 영속성 로직을 수행하는 것을 가능하게 한다.
이 주제에 대해서는 논의가 많다. 사실, 개인적인 입장에서는 DAO를 사용하더라도 도메인 레이어에 속하는 Repository와 같은 interface를 이용하여 구현하면(데코레이팅) 충분히 Repository처럼 사용할 수 있다고 생각한다.
하지만 내 생각에서 가장 베스트는, 애초의 둘은 설계관점, 이용 목적부터 다르기때문에 혼용해서 사용하기 보다는 그냥 서로 목적에 맞게 사용하는게 최고일 듯 하다.
A. Hibernate와 JPA가 제공하는 API를 사용하면 자바 객체(Object)를 (Relation) 테이블에 매핑할 수 있습니다.
그래서 Object Relation Mapper라고 부릅니다.
B. 반면에 ibatis 같은 경우에는 java bean에 대한 매핑이 아니라 SQL에 대한 매핑입니다.
그래서 SQL매퍼라고 부릅니다.
따라서 A의 경우에는 매핑 레벨이 객체 수준이고 B는 SQL 수준이기 때문에
B는 각 데이터베이스 시스템에 대한 의존성을 가지고 있고 원글에서처럼
전체 아키텍처 관점에서 데이터를 엑세스할 수 있는 하나의 창구 (Facade)의 역할을 수행하지만
실제 구현시에는 위와 같은 차이를 지니고 있기 때문에
얼마 전 지인으로부터 DAO(Data Access Object)와 REPOSITORY의 차이점에 관해 설명해 달라는 요청을 받았다. 대부분의 소프트웨어 개발 이슈가 그렇듯이 이런 류의 질문에 대한 대답은 미묘하지만 격렬한 논쟁을 불러 일으키기 쉽다. 논쟁의 중심에는 항상 극단적인 순수주의와 허무주의 간의 충돌이 존재하며, 파국의 소용돌이 속에서 개념적 편향을 막기 위한 최선의 방법은 논쟁의 대상이 출현하게된 배경과 현재의 개념이 정립되기까지의 과정을 살펴 보는 것이다.
1990년대 말에 등장한 EJB(Enterprise Java Beans)는 Java의 ‘Write Once, Run Anywhere’ 모토를 엔터프라이즈 어플리케이션 환경으로 확장하기 위한 Sun의 야심작이다. EJB 의 중심 전략은 분산, 트랜잭션, 퍼시스턴스, 보안 등의 인프라스트럭쳐 서비스는 WAS(Web Application Server)에서 제공하고 어플리케이션 개발자는 비즈니스 로직에만 집중하도록 하자는 것이다. 개발자들은 Sun에서 제시하는 장미빛 미래에 열광적으로 환호했고, WAS라는 프론티어를 향한 벤더들의 골드 러시는 EJB가 21세기의 은총알일 것이라는 신기루를 만들어 냈다.
초기 J2EE에서 권장한 기본 아키텍처는 도메인 레이어를 EJB Session Bean으로, 퍼시스턴스 레이어를 EJB Entity Bean으로 구성하는 것이다. Entity Bean은 O/R Mapper(Object–Relational Mapper)의 원시적인 형태로 최근 Ruby On Rails의 인기로 인해 주목받고 있는 ACTIVE RECORD 패턴을 적용한 퍼시스턴스 기술이다. Entity Bean은 CMP(Container-Managed Persistence)의 매핑 제약, BMP(Bean-Managed Persistence)의 비유용성, 오버헤드, 빈약한 EJB QL 지원, 침투적인 인프라스트럭쳐 코드, 복잡도 등의 단점으로 인해 개발자들로부터 외면을 받고 말았다.
Entity Bean이 무대의 뒷편으로 쓸쓸히 퇴장할 운명에 처한 반면 선언적으로 트랜잭션을 정의할 수 있는 CMT(Container-Managed Transaction) 기반의 Session Bean은 다양한 어플리케이션에서 폭 넓게 사용되었다. 그러나 Entity Bean을 무시한 채 Session Bean만을 사용하기 시작하면서 부터 한가지 문제점이 발생했다. 비즈니스 로직만을 담아야할 Session Bean 내부로 퍼시스턴스 로직이 침투하기 시작했던 것이다. Session Bean과 Entity Bean에 의해 자연스럽게 구분되던 도메인 레이어와 퍼시스턴스 레이어 간의 경계가 모호해지면서 Session Bean 내에 비즈니스 로직과 퍼시스턴스 로직이 섞여 버리는 경우가 많았다. 이를 해결하기 위해 퍼시스턴스 저장소로 접근하는 모든 로직을 캡슐화하는 별도의 객체를 추가하여 도메인 레이어와 퍼시스턴스 레이어를 명확하게 분리하는 방법이 제시되었다. 이처럼 Entity Bean의 퍼시스턴스 지원 기능을 대체하는 동시에 비즈니스 로직과 퍼시스턴스 로직의 명화한 분리를 위해 퍼시스턴스 로직을 캡슐화하고 도메인 레이어에 객체-지향적인 인터페이스를 제공하는 객체를 DAO(Data Access Object) 라고 한다.
REPOSITORY는 Domain-Driven Design 의 기본 빌딩 블록 중 하나로 도메인 레이어에 객체 지향적인 컬렉션 관리 인터페이스를 제공하기 위해 사용되는 PURE FABRICATION이다. 변경에 대한 불변식을 유지하기 위해 하나의 단위로 취급되면서 변경의 빈도가 비슷하고, 동시 접근에 대한 잠금의 단위가 되는 객체의 집합인 AGGREGATE 별로 하나의 REPOSITORY를 사용한다. 예를 들어 Order와 OrderLineItem이 하나의 불변식을 공유하는 단위이고 OrderLineItem의 생명 주기가 Order에 종속된다면 OrderRepository를 사용해서 모든 Order와 OrderLineItem 컬렉션을 관리한다.
REPOSITORY를 설명하면서 의도적으로 컬렉션이라는 용어를 반복해서 사용했다는 점에 주목하기 바란다. REPOSITORY는 특정 객체 집합의 가상적인 메모리 컬렉션을 관리한다. 시스템에 1억건의 주문 정보가 존재한다면 OrderRepository는 1억건의 Order 인스턴스와 그와 관려된 OrderLineItem 인스턴스가 메모리 내에 로드되어 있다고 가정한다. 클라이언트는 OrderRepository를 사용해서 Order 컬렉션을 처리한다. 전체 컬렉션에 Order 인스턴스를 추가하기도 하고, 컬렉션에서 특정 Order 인스턴스를 제거하기도 하고, 일정 기간 동안의 Order 개수를 카운트하기도 한다. 여기서 중요한 것은 REPOSITORY 자체는 퍼시스턴스 메커니즘에 대한 어떤 가정도 하지 않는다는 점이다. REPOSITORY를 사용할 때는 이미 모든 Order 객체와 OrderLineItem이 메모리에 로드되어 있다고 가정하고 메모리에 로드된 특정 객체, 객체 집합, 전체 객체에 접근하기 위해 REPOSITORY를 사용한다.
REPOSITORY는 문제 도메인 분석 과정에서 도메인 레이어에 속하는 객체들에게 객체-지향적인 컬렉션 인터페이스를 제공하기 위한 용도로 도메인 모델에 추가된다. 따라서 REPOSITORY는 도메인 모델의 일부이며 UBIQUITOUS LANGUAGE의 한 요소이다. 비록 REPOSITORY 자체는 도메인 모델에 속하지만 REPOSITORY 내부에서는 AGGREGATE의 생명 주기를 관리하기 위해 하부의 퍼시스턴스 메커니즘을 사용할 필요가 있다. 그러나 REPOSITORY에 퍼시스턴스 로직이 포함될 경우 REPOSITORY를 직접 사용하는 도메인 객체 역시 퍼시스턴스 메커니즘에 의존하게 되는 부작용이 발생한다. 이를 해결하기 위한 최선의 방법은 REPOSITORY를 인터페이스와 구현부로 분리한 후 인터페이스는 도메인 레이어에 속하도록 하고, 구현부는 퍼시스턴스 레이어에 속하도록 하는 것이다. 이처럼 DIP(Dependency Inversion Principle)에 기반하여 인터페이스와 구현부 사이의 계층을 분리하는 패턴을 SEPARATED INTERFACE이라고 한다.
DAO와 REPOSITORY 모두 퍼시스턴스 로직에 대한 객체-지향적인 인터페이스를 제공하고 도메인 로직과 퍼시스턴스 로직을 분리하여 관심의 분리(separation of concerns) 원리를 만족시키는데 목적이 있다. 그러나 비록 의도와 인터페이스의 메소드 시그니처에 유사성이 존재한다고 해서 DAO와 REPOSITORY를 동일한 패턴으로 취급하는 것은 성급한 일반화의 오류를 범하는 것이다.
- DAO는 퍼시스턴스 로직인 Entity Bean을 대체하기 위해 만들어진 개념이다. DAO가 비록 객체-지향적인 인터페이스를 제공하려는 의도를 가지고 있다고 하더라도 실제 개발 시에는 하부의 퍼시스턴스 메커니즘이 데이터베이스라는 사실을 숨기려고 하지 않는다. DAO의 인터페이스는 데이터베이스의 CRUD 쿼리와 1:1 매칭되는 세밀한 단위의 오퍼레이션을 제공한다. 반면 REPOSITORY는 메모리에 로드된 객체 컬렉션에 대한 집합 처리를 위한 인터페이스를 제공한다. DAO가 제공하는 오퍼레이션이 REPOSITORY 가 제공하는 오퍼레이션보다 더 세밀하며, 결과적으로 REPOSITORY에서 제공하는 하나의 오퍼레이션이 DAO의 여러 오퍼레이션에 매핑되는 것이 일반적이다. 따라서 하나의 REPOSITORY 내부에서 다수의 DAO를 호출하는 방식으로 REPOSITORY를 구현할 수 있다.
- Core J2EE Patterns나 기타 J2EE 서적에서 언급하고 있는 것처럼 DAO는 데이터베이스 뿐만 아니라 B2B, LDAP, 메인 프레임, 레거시 시스템과 같은 다양한 종류의 외부 시스템과의 상호작용을 캡슐화하기 위해 사용될 수 있다. 이 경우 DAO는 외부 시스템에 대한 GATEWAY 역할을 수행한다. 그에 비해 REPOSITORY는 객체 컬렉션 처리에 관한 책임만을 가지고 있다. Domain-Driven Design에서 외부 시스템과의 상호작용은 별도의 SERVICE가 담당한다.
- DAO는 퍼시스턴스 레이어에 속한다. 반면 REPOSITORY의 인터페이스는 도메인 레이어에 속한다.
- 대부분의 프로젝트에서 TABLE DATA GATEWAY 패턴을 따라 테이블 별로 하나의 DAO를 만든다. 이 전통은 Entiry Bean을 DAO로 대체하면서 테이블 당 하나의 Entity Bean을 만들어야 했던 EJB의 제약을 그대로 답습한 것이 아닌가 추측된다. 이유야 어떻든 현재 DAO를 개발하는 일반적인 패턴은 DB에 존재하는 테이블 당 하나의 DAO를 사용하는 것이며, 이것은 DAO가 인터페이스 차원에서는 데이터베이스에 대한 의존도를 캡슐화할 수 있다고 하더라도 테이블 변경에 대해서는 투명하지 않다는 것을 의미한다. REPOSITOR의 인터페이스는 AGGREGATE ROOT(또는 Entry Point)와 관련된 오퍼레이션만을 포함하며 따라서 테이블 변경에 대해서 투명하다.
- DAO는 TRANSACTION SCRIPT 패턴과 함께 사용된다. 반면 REPOSITORY는 DOMAIN MDOEL 패턴과 함께 사용된다.
- 마지막으로 가장 중요하면서도 분명한 차이점은 두 빌딩 블록을 식별하는 과정에서 나타난다. REPOSITORY는 도메인 모델링 단계에서 하나의 개념 단위로 묶인 AGGREGATE를 도출하는 과정에서 자동으로 식별된다. 이것은 REPOSITORY 식별 과정이 도메인 규칙에 영향을 받는다는 것을 의미한다. 앞에서 설명한 바와 같이 DAO는 TABLE DATA GATEWAY 패턴에 따라 데이터베이스 테이블 별로 생성되는 것이 일반적이며 퍼시스턴스 레이어에 대한 FACADE 역할을 수행한다. 따라서 DAO 식별 과정은 도메인 규칙 보다는 데이터베이스 테이블의 단위에 영향을 받는 경향이 강하다.
지금까지 DAO와 REPOSITORY의 개념적 차이를 살펴보았다. 최근의 기술 흐름으로 살펴 보았을 때 앞서 설명한 차이점이 그렇게 중요한 것은 아니라고 생각된다. 가장 큰 이유는 Spring과 Hibernate와 같은 경량 프레임워크가 EJB를 누르고 산업계의 표준으로 등장함에 따라 EJB 세계에서 통용되던 다양한 개념과 용어들이 POJO(Plain Old Java Object) 기술의 성장에 따라 확장을 계속하고 있기 때문이다.
이런 맥락에서 볼 때 DAO와 REPOSITORY 간의 논쟁 역시 Entity Bean을 대체하기 위한 용도로 등장했던 DAO가 EJB의 제약을 벗어나 REPOSITORY와 유사해 지는 과정에서 불거진 것이라고 볼 수 있다. Rod Johnson 역시 그의 저서 Expert One-On-One J2EE Development without EJB에서 O/R Mapper를 사용할 경우의 DAO 패턴을 REPOSITORY와 유사한 개념으로 설명하고 있다. 차이점이라면 AGGREGATE의 개념을 first-class domain object와 dependent object로 표현하고 있다는 정도 뿐이다. Rod Johnson의 예에서 알 수 있듯이 기술적인 측면에서만 본다면 DAO와 REPOSITORY 간의 차이점을 논하는 것이 무의미할 정도로 두 패턴이 많은 유사성을 띄고 있음을 알 수 있다.
그럼에도 불구하고 DAO와 REPOSITORY를 동일하게 취급하는 것은 올바른 접근 방법이 아니다. 비록 두 패턴이 기술적으로 점점 유사성을 띄어 가고 있다고 하더라도 DAO는 퍼시스턴스 레이어에 속하는 FACADE이며, REPOSITORY는 순수한 도메인 모델 객체이다. DAO는 퍼시스턴스 로직의 요구사항에 따라 설계되는 반면 REPOSITORY는 문제 도메인의 요구사항에 따라 설계된다.
개인적으로 TRANSACTION SCRIPT 패턴에 따라 도메인 레이어가 구성되고 퍼시스턴스 레이어에 대한 FAÇADE의 역할을 하는 객체가 추가될 때는 거리낌 없이 DAO라고 부른다. 도메인 레이어가 DOMAIN MDOEL 패턴으로 구성되고 도메인 레이어 내에 객체 컬렉션에 대한 인터페이스가 필요한 경우에는 REPOSITORY라고 부른다. 결과적으로 두 객체의 인터페이스의 차이가 보잘 것 없다고 하더라도 DAO가 등장하게된 시대적 배경과 현재까지 변화되어온 과정 동안 개발 커뮤니티에 끼친 영향력을 깨끗이 지워 버리지 않는 한 DAO와 REPOSITORY를 혼용해서 사용하는 것은 더 큰 논쟁의 불씨를 남기는 것이라고 생각한다.
Reference
https://www.slipp.net/questions/319
http://egloos.zum.com/aeternum/v/1160846
https://bperhaps.tistory.com/entry/Repository%EC%99%80-Dao%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90
https://github.com/msbaek/memo/blob/master/dao-vs-repository.md
'질문 & 답변' 카테고리의 다른 글
| 트러블 슈팅 (feat. Eureka AWS 배포하기) (0) | 2021.10.08 |
|---|---|
| Agile pull requests (feat. PR관리방법) (0) | 2021.08.01 |
| "@Retention @Target "은 어떤 역할을 할까? (feat. 커스텀 어노테이션 인터셉터에 적용하기) (0) | 2021.07.11 |
| "Mapper / DAO" 의 차이점은 무엇일까? (0) | 2021.07.08 |
| "AOP / 필터 / 인터셉터"는 어떤 차이가 있을 (0) | 2021.07.08 |